In April 2026, the New York Times ran an opinion piece titled "Silicon Valley Is Bracing for a Permanent Underclass." This report takes the question that piece raised as its starting point and works through the economic structure of a world in which AI progressively substitutes for labor, reasoning one step at a time within established economic frameworks, then putting that reasoning through verification against primary sources.
At the center is a single question: does AI produce a permanent underclass? I break it into five sub-questions and take them in order. What gates AI substitution? Which jobs disappear, when, and what is born in their place? Who captures the excess profit AI generates? In that concentrated world, what can an individual (and a business) still stand on? And does the demand hold up: does AI grow the pie itself? Each of the five is developed across several parts in the body.
Let me give the conclusion first. Followed by logic alone, the analysis arrives somewhere dark: "a permanent underclass is a stable equilibrium." But the moment empirical data enters, the conclusion steps down a notch. The most likely scenario is not a civilizational ending but partial substitution proceeding through periodic financial crises: a world closer to Minsky than to Marx. The reprieve, though, is not a wall but a clock, and that clock keeps ticking forward.
And what finally came into view is this: whether the picture is pessimistic or optimistic is not a question of fact but a question of which metric you measure by. Measured in excess profit (rent) wealth concentrates, and the picture is grim. But measured in benefit, in what people actually receive, AI can be the most equalizing technology in history, putting expert-grade capability into more hands than ever before. Roughly 93% of the value sits outside rent, on the benefit side. Where we are heading is a future split in two: access to capability more equal than ever, wealth more concentrated than ever.
All figures are as of mid-2026 and rest on primary sources including Epoch AI, METR, the World Economic Forum, the EU AI Act, Stanford's Digital Economy Lab, and the NBER. Verification used a generative-AI research harness (roughly 100 search agents, ~25 primary sources, and a 3-vote fact-check per run) across 17 runs in total; claims that did not pass were removed from the text.
The meme's claim runs like this. The time people have left to build assets is already short, and once AI and robots advance far enough to displace human labor wholesale, we will be frozen in our current class positions. The rich will live commanding superintelligence; everyone else will be deemed surplus and live on what welfare remains. The piece even reports the early signs of the backlash, the quiet arson, the gallows humor of engineers automating their own jobs, the boardroom anxiety.
To test this claim, I used a two-stage method. First, build the logic using established economic frameworks: the economics of tort law, industrial organization, the theory of complementary assets, the theory of effective demand. Then check the facts that logic presupposes against primary sources. This order (reason first, reconcile after) mattered. If you let AI produce the answer first, you lose the chance to calibrate your own judgment. The division of labor is: logic paints the worst-case picture, evidence tells you where the ceilings and the brakes actually are. As it turned out, the logic ran all the way down to a stable, frozen underclass; the evidence then pulled it back to something more like a violent business cycle. The gap between those two is the most useful thing in the whole exercise, and it is most of what this report is about.
Two principles run through the entire analysis, and I want to put them up front.
The first I call the calculability clock. AI is strong in domains where the correctness of an outcome can be checked automatically and cheaply, or where the world can be simulated. It is weak in the messy real, judgment riddled with exceptions, the manipulation of physical objects. This single principle governs the speed at which cognitive labor is substituted, the limits on physical labor, and the location of the excess profit the frontier models earn, all at once. It is the spine that connects parts that otherwise look unrelated.
The second is Varian's principle of complements: become a complement to what is becoming cheap and ubiquitous; do not become its substitute. The more AI cheapens cognitive execution, the scarcer its complements become: trust, accountability, relationships, meaning. Pair this with Teece (1986): when the core of an innovation commoditizes, the profit flows not to the innovator but to whoever owns the scarce complementary assets around it. Together they tell you where value drains from and where it pools to.
TL;DR: What decides whether AI takes a job is not capability but whether the errors are insurable. Deployable automation = min(capability, the insurability of the residual error). Keeping a human in the loop is only transitional.
"Which jobs will AI take?" Most discussions rank jobs by how hard they are. I think that is the wrong axis. The first claim of this report is that what determines AI substitutability is not technical capability but whether responsibility can be borne. As an equation:
Deployable automation = min( technical capability, the insurability of the residual error )
That it is a min function is the crux. Even at 100% capability, if there is no party able to bear responsibility for the remaining errors, deployment stays at zero. Self-driving cars were "almost ready" for over a decade precisely because the right-hand term was jammed, not the driving, but the question of who eats the cost when the system is wrong one time in ten thousand.
Reduce tort law to its economics and it appears to ask "who is at fault," but it really asks "who can bear that loss most cheaply, and is willing to" (Calabresi's "cheapest cost avoider," 1970). Deployment happens the instant a sufficiently capitalized party can price the residual error actuarially and decides to own it. And that is exactly what happened. Waymo runs without a driver and carries the liability for its crashes itself. Mercedes's Level 3 system accepts liability while it is engaged. It was less that the technology crossed a line than that the insurance math did. This reframing matters because it tells you the binding constraint is financial and legal, not technical, and financial constraints move on their own clock.
The speed at which a job's errors become insurable (and the human is quietly removed from the loop) is set by four things.
Table 1, The four dimensions of insurable responsibility
| Dimension | Substituted quickly | Persists longer |
|---|---|---|
| Damage per incident | Small | Large |
| Irreversibility | Reversible | Irreversible |
| Actuarial predictability | High (substituted early) | Low |
| Identifiability of the victim | Low | High |
Only the third points the other way: the more predictable, the sooner substituted. Radiology was technically automatable years ago but survived, because a missed diagnosis is irreversible and licensing restricts who may sign off. The call center had no such shield, and it fell the moment capability arrived.
There is a dark corollary here that recurs later. The professions whose entire expertise is the pricing of risk (underwriters, actuaries, credit analysts) turn out to be among the most exposed, precisely because their domain is the most measurable, and because the firms that employ them already sit on the data needed to replace them. The cobbler's children go barefoot.
On this logic, the human-in-the-loop (HITL) arrangement is not a destination. It is a transitional state that lasts only while the actuarial data is too thin to price the error, and no longer.
And even where the human remains, much of it persists in a degraded form, what Madeleine Elish (2019) called a "moral crumple zone." The human is kept not because they catch the machine's errors but as the party to blame when there is an accident. The automation overconfidence repeatedly confirmed in aviation shows that the more accurate the system, the more humans stop verifying (Parasuraman and Riley, 1997). The power to catch the remaining 0.01% was the only reason to keep the human, and that power erodes through the very overconfidence the system's accuracy creates. The crumple zone keeps the role on the org chart while hollowing out its actual function.
Even if the structure of responsibility requires HITL, what it protects is only the existence of the job, not the level of the wage. A rubber-stamp role anyone can fill makes the labor supply effectively infinite, and the wage is competed down to the floor. What supports the wage is not the structure of responsibility but the supply restriction imposed by licensing (Kleiner and Krueger, 2013). This distinction (job-survival versus wage-survival) becomes decisive later, in the discussion of industry resilience, where several "safe" professions turn out to be safe in body and gutted in pay.
TL;DR: The speed of substitution is set by the "calculability clock" and arrives in three waves. The professions that price risk fall first; capability's arrival can briefly raise headcount (Jevons) before it falls. The market polarizes to both ends, hollowing out the middle.
The speed at which a profession's errors become actuarial is set by five factors, operating separately from technical capability.
Table 2, The five factors of the calculability clock
| Factor | Fast (substituted early) | Slow (persists longer) |
|---|---|---|
| Frequency / volume of decisions | High frequency, high volume | Rare |
| Homogeneity of cases | Homogeneous, repetitive | One-off, varied |
| Speed of outcome feedback | Right/wrong known immediately | Years later, ambiguous |
| Scale and reversibility of the worst case | Small, reversible | Catastrophic, irreversible |
| Ease of causal attribution | Separable from AI's error | Indistinguishable from noise |
"How smart the AI is" is less useful for prediction than "how fast that job's errors become actuarial." The clock, not the benchmark, is the predictor.
Table 3, The three waves of substitution
| Wave | Timing | Character | Affected roles |
|---|---|---|---|
| Wave 1 | 0–2 years (under way) | Digital-only, high-frequency, low-risk, no liability problem | Call centers, data entry, routine copy, translation, junior development |
| Wave 2 | 2–4 years | Professional, but the actuarial base already exists | Financial analysts, consulting deliverables, audit, contract law, insurance underwriting |
| Wave 3 | 4 years+ | Physical, catastrophic risk, one-off | Surgery, complex diagnosis, trial advocacy, executive judgment, skilled trades |
First: the professions that calculate risk are the first to be calculated away. Underwriters, actuaries, credit assessment, risk management. These lead Wave 2, for the reason given in Part 1, their domain is the most calculable and their employers already hold the data automation needs.
Second: by Jevons's paradox, some professions actually grow right after capability arrives. In 2016 Hinton said radiologists should stop being trained: they would be replaced by AI within five years. Yet from 2016 to 2023, the number of radiologists rose. As AI cheapened reading, the volume of imaging requests exploded, and total demand (price times volume) swelled. Capability arriving does not mean immediate decline. Capability lands, induced demand lifts the numbers for a while, then the calculability clock catches up and they finally begin to fall. Miss this S-curve lag and you misread how fast the clock is moving, in either direction.
The jobs that are newly born are mostly low in labor intensity. As a result the labor market polarizes toward both ends. The high-skill end (work that wields AI, work that bears responsibility, entrepreneurship) and the low-skill end (interpersonal care, the trades) survive, while the white-collar middle hollows out. And once the middle is gone, the very path from the low end up to the high end disappears with it. This is not only a market-level shape; inside an organization it shows up as flattening, and it connects directly to the hollowing of the career ladder discussed in Part 4 and Part 7.
TL;DR: The three frontier labs hold share and revenue, but durable rent splits along the time horizon. Open weights ~3 months behind cap the price, and lock-in is weak in the data, share ≠ rent. Only the true frontier is now being gated off.
This was the most contested part of the inquiry, and it rewards the most detail. The short version: the three frontier labs hold share and revenue robustly, but durable rent (margin) splits along the time horizon, and the moat that the bull case assumes turns out, on inspection, to be thin.
The surge in AI software development looks at first like Jevons-induced demand. But its demand has a decisively different backing from radiology reading.
Table 4, Two kinds of Jevons
| Exogenous-demand type | Speculative-demand type | |
|---|---|---|
| Example | Radiology reading | AI software development |
| Source of demand | External willingness to pay (the sick, insurance reimbursement) | A bet on future revenue |
| Reversal risk | Low | High (evaporates if revenue never arrives) |
| Nature | Robust, one-directional | Recursive, two-directional (Soros-reflexive) |
Software development exploded because "anyone can build now," but most of those projects are unproven bets, and their fuel is venture capital plus corporate experiment budgets. In the gold-rush framing the foundation-model labs are the pickaxe sellers, and a substantial share of their revenue is therefore circular: it rests on the miners' capital, not on the miners' realized earnings. If the conviction spreads among the miners that "the gold isn't coming," pickaxe demand contracts with it. The exception is the sensitive, high-value enterprise core, where exogenous real demand puts a genuine floor under the revenue. So the pickaxe seller is partly insulated and partly exposed, a distinction that returns, sharpened, in Part 5 and Part 6.
On the surface the three labs building the most advanced models (OpenAI, Anthropic, and Google DeepMind) look like a durable oligopoly. Walk through the candidate challengers and each one falls.
Table 5, Market-structure map (threat assessment)
| Threat | Assessment | Basis |
|---|---|---|
| Independent VC-backed startups | Cannot challenge | Capital markets demand a "catch-up, moat, profit" story and cut funding. Inflection→Microsoft, Adept→Amazon, Character→Google (reverse acqui-hires) |
| Chinese models (DeepSeek, etc.) | A separate sphere | Geopolitics and data governance wall them off; Western enterprise cannot adopt the API on compliance grounds |
| OSS / sovereign (Llama, Gemma, Mistral, Nemotron) | Cannot take share | Not competitors but instruments — Meta to commoditize a complement, NVIDIA to create GPU demand, Google for mindshare, sovereigns for strategic autonomy |
| High-value work | Captured by the top 3 | The premium concentrates |
| Commodity tier | The floor caps the ceiling | OSS's ~3-month lag holds prices down |
The crucial move here is on the open-weight row. Frontier financing has migrated from venture capital (whose return math no longer closes) to hyperscaler strategic capital and sovereign money. And that same migration leaves, outside the top three, a large pool of non-VC capital whose objective function is not "return" but "commoditize the complement" or "strategic autonomy." That is exactly the capital that funds open weights. Open weights are not trying to win the rent; they are trying to destroy it for everyone. A competitor you cannot starve of funding, because it was never seeking a return, is a different kind of force from a startup challenger.
A natural intuition (one that came up in the analysis) is that this will settle like the telecom carriers: three majors that never start a price war, with open-weight and sovereign models playing the role of cheap MVNOs (low price, lower quality), and a stable segmentation by quality tier.
The industrial-organization mechanics behind that intuition are real. Enormous sunk fixed costs produce a natural oligopoly. A small number of players (three) supports tacit coordination by the folk theorem. Capacity constraints push the game toward Cournot competition, which (unlike Bertrand price competition) leaves a positive margin standing. So far the analogy holds.
But it rests on a hidden assumption: telecom's stable equilibrium is a capability-plateau equilibrium. "Similar quality across carriers" means capability has topped out and homogenized. If capability keeps jumping discontinuously, the equilibrium is unstable, and the tiers do not stay put.
And the MVNO half of the analogy breaks outright:
Telecom MVNO: subordinate to the incumbent's infrastructure
(leases wholesale capacity, gets throttled at congestion)
→ segmentation is stable
Open weights: independent (self-trained, neutral cloud, cannot be throttled)
→ can raise their own quality autonomouslyThe right reference class for a low-price entrant that independently improves its own quality is not the MVNO but Christensen's low-end disruption, Unix → Linux, minimills in steel, Japanese cars. "Most large enterprises will choose the high-quality option" is precisely the line incumbents always deliver just before low-end disruption catches them. Two further disanalogies seal it: radio spectrum is legally scarce (a national license), whereas compute and model weights carry no legal exclusivity; and telecom never had to contend with a free substitute that improves every single year. Open weights are that substitute.
This is the hinge of the whole part. Coca-Cola defends its share against chemically identical private labels through brand and distribution, and still cannot charge a hundred times the generic price. The top three can hold share (distribution, brand, switching habits) while still being unable to hold a thick margin, because on general capability the best open-weight models trail the most advanced models by only about three months (Epoch AI), sometimes closing to zero. A free substitute three months behind and still improving puts a hard ceiling on the price of intelligence-as-commodity. Holding share and earning durable rent are different facts, and they are entirely compatible. Share ≠ rent.
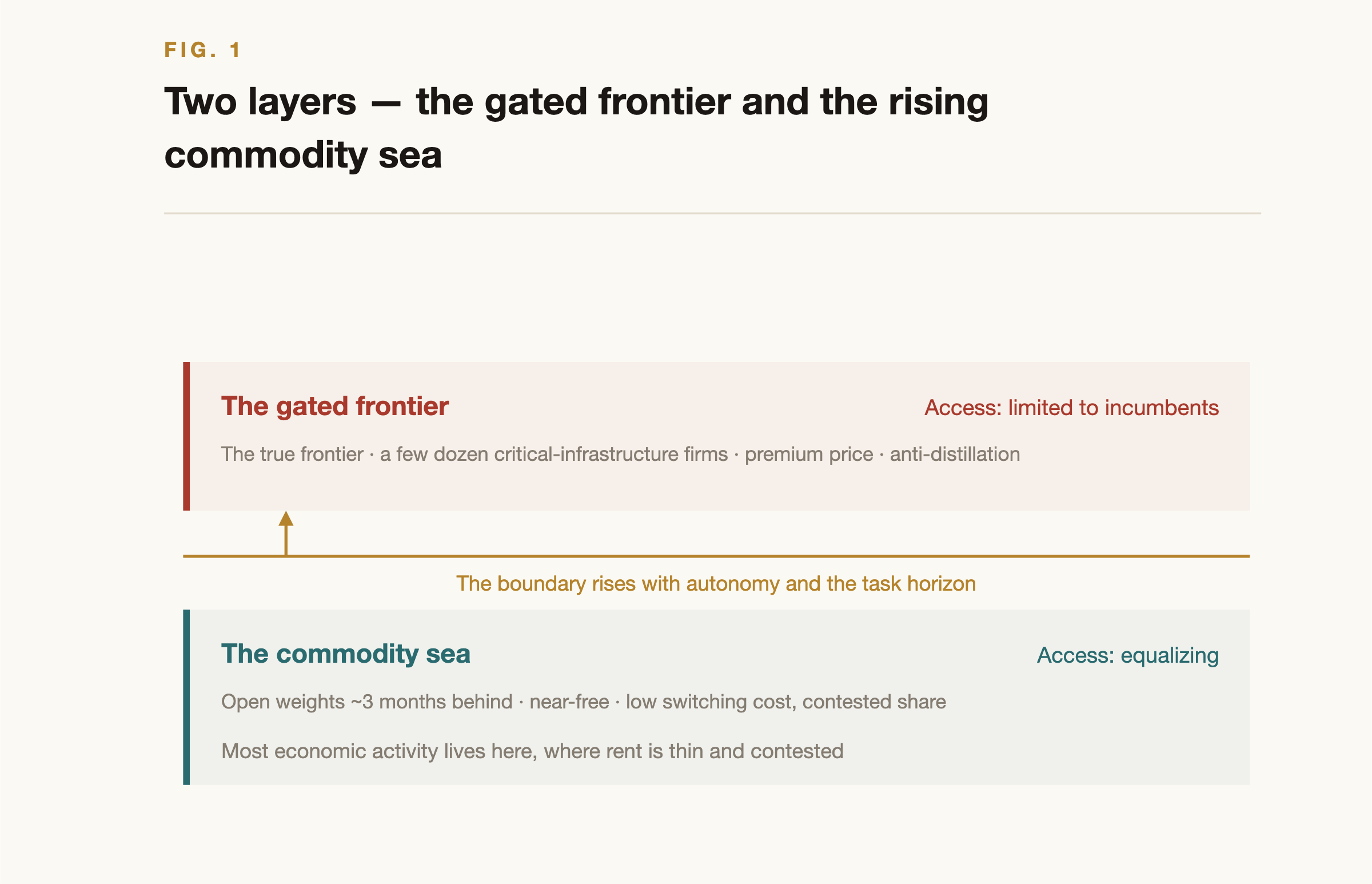
Figure 1, Two layers. Below the line, access to intelligence trends toward free; above it, the most advanced models are confined to incumbents. The boundary keeps rising.
So where does durable rent actually survive? Not between cheap work and expensive work, but inside the expensive work.
Inside a high-value agentic workload (large budget):
· the hard planning step → frontier (high unit price) ← ~10% of tokens
· tool calls, retrieval, summarizing, boilerplate code → cheap/floor model (low unit price) ← ~90% of tokensThe floor binds not on "cheap jobs" but on the large commodity-token fraction inside high-value jobs, and as work becomes more agentic, that fraction grows. The labs treat the commodity tier as a customer-acquisition cost, giving it away near-free, and recoup at the frontier (the Amazon commerce-plus-AWS structure). Lock-in, in this picture, is not between providers but within one, getting you to switch optimally between, say, a flagship and a small model inside the same vendor.
That framing has three consequences. First, the cross-subsidy quietly reintroduces dependence on the frontier premium: the money that subsidizes the commodity tier is the frontier margin, so if the frontier premium compresses (a scaling plateau), the cross-subsidy collapses. Second, the moat moves from "model quality" to "distribution and lock-in", which means the true competitor is the distribution platform (Google's Workspace/Android/Chrome/Search, Microsoft's Office/Windows, Apple's devices), and the incumbent integrates forward into the model layer. Third, platform lock-in has increasing returns, so the end state may tip more concentrated than telecom, closer to "one dominant plus two followers, with margins diverging" than to "three abreast."
Here the evidence overturned a prediction. Enterprise model spending sloshes between labs: over two years one leading firm's share of enterprise spend fell from roughly 50% to about 27%, while a rival's rose from about 12% to roughly 40%. That is the signature of a contested, low-switching-cost market, not a captured one. The theoretical AWS-style moat exists on paper, but in the measured data share is contestable: the best model wins the quarter, and no one holds a captive customer. This is the same story as the thin OSS moat and share≠rent, seen from the demand side.
And yet, at the very top, the opposite move is now visible. The labs have begun gating the true frontier outright. Anthropic's most capable model to date was not released broadly; through a program reported as "Project Glasswing" it went to a few dozen vetted critical-infrastructure firms (the kind of names that sit at the center of the economy) at several times the price of the generally available tier, framed partly as a safety measure and partly, in practice, as a defense against distillation (the labs have publicly accused competitors of siphoning their models at industrial scale). So two things happen at once: ordinary intelligence races toward free while the real frontier quietly becomes members-only. That gated access is itself a new complementary asset, and, tellingly, it is handed to precisely the incumbents who already hold capital, distribution, and data. The stated motive is safety and may be temporary; whether it hardens into a permanent moat is unresolved, and the gap between gated and open has not yet been measured. But the two-tier structure is now real rather than hypothetical, and it sets up the inequality that Part 4 traces down to the individual.
TL;DR: What divides value is not AI access but complementary assets, Set A (structurally concentrating) versus Set B (an individual can build). Within Set B, against conventional wisdom, taste and judgment are the weakest; accountability, trust, and relationships persist. But the ladder for building them is being pulled up.
In a world where commodity AI is distributed near-free as a customer-acquisition cost, access to AI equalizes. The line that divides who captures value moves to the complementary asset you pair the AI with. What AI commoditizes is cognitive execution, which happens to be the entire foothold of the twentieth-century professional middle class. When their complementary asset (trained cognitive labor) loses its value, value flows to the assets that do not commoditize.
Applied to individuals, complementary assets split in two.
Table 6, The two sets of complementary assets
| Set | Contents | Can an individual acquire it? |
|---|---|---|
| Set A (structurally concentrating) | Capital, mass distribution, energy and compute, large proprietary datasets, privileged access to the gated frontier models | Hard |
| Set B (an individual can build over time) | Trust and track record, relationships, the standing to bear responsibility, judgment and taste, a niche audience | Yes |
Set A concentrates by its own logic, capital compounds (r > g), distribution aggregates toward winner-take-most (Ben Thompson's aggregation theory: when supply is free, demand-side aggregation is the only bottleneck), and the gated frontier (Part 3) is now an explicit Set A item handed to existing capital holders. Set B is the part an individual can accumulate through time and experience, and it shares one property: every item sits at a layer above execution: what to make, the power to vouch that something is right, whom to work with, the standing to make a decision and own its consequences. Exactly the layers AI does not touch.
Conventional advice says "climb toward upstream judgment and taste." This points the wrong way. Even within Set B, durability is decided by why the asset resists AI, and there are only two sources of resistance: a capability moat ("AI can't do this well yet", temporary, expiring as models improve; it is just further back in the same queue the calculability clock describes) and a legitimacy moat ("even if AI did this perfectly, the value still requires a human who can be trusted, held responsible, or related to", durable, because it was never a claim about capability but a social fact about who).
Table 7, The durability ranking within Set B
| Asset | Type of moat | Shelf life |
|---|---|---|
| Standing to bear responsibility | Legitimacy (accountability) | Longest |
| Relational capital | Legitimacy (reciprocity) | Long |
| Trust / track record | Legitimacy (provenance) | Core long, shell short |
| Niche distribution / personal brand | Mixed | Medium to long |
| Taste / judgment | Capability | Shortest |
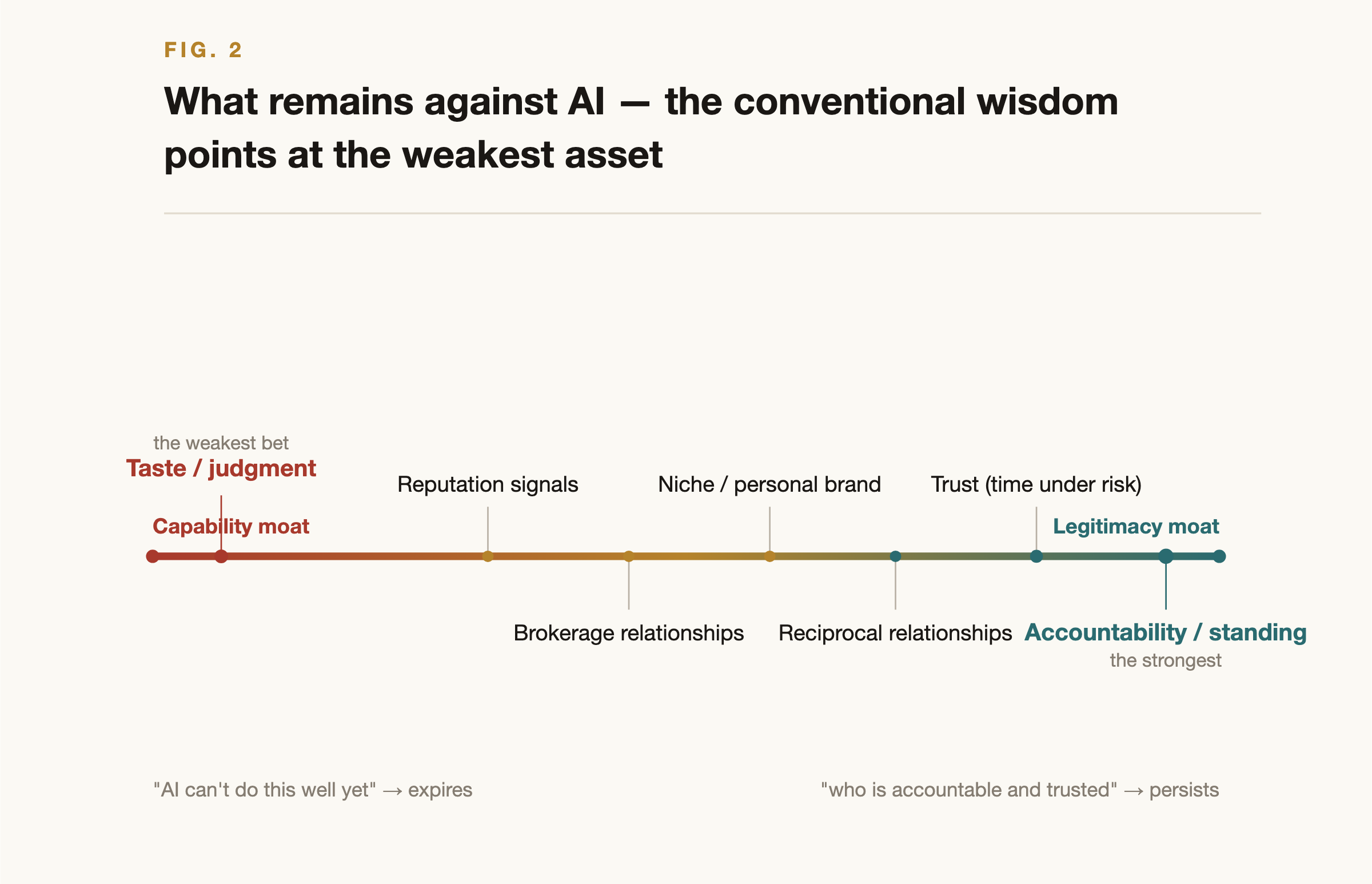
Figure 2, The durability ranking of complementary assets. The capability moats on the left (taste, judgment) expire; the legitimacy moats on the right (accountability, trust, relationships) persist.
The counterintuitive headline: taste and judgment are the weakest bet in Set B. "Discern the good thing, judge correctly" is a pure capability claim, and capability is the one thing reliably going up: it is exactly what the benchmarks measuring judgment and evaluation are now climbing. The most human-seeming asset is the one most firmly on the clock. What persists are the unglamorous assets: the genuine standing to bear responsibility, structurally impossible for a machine that cannot be sued, fined, or shamed; the trust that can only be accumulated through time spent exposed to risk; the reciprocal relationship a machine cannot hold on your behalf. The durable move is not "out-judge the AI" (you won't) but "be the accountable, trusted human the AI cannot, legally or socially, be." And note the recursion trap: wherever AI makes building Set B easier and faster (mass-posting your way to a personal brand), everyone can do it and it commoditizes; the durable core is precisely what AI cannot forge or shortcut.
There is even a deeper dependency. The durability of the strongest moat (the legitimacy of accountability) itself rests on a political variable: whether society grants AI legal personhood and accountability. The article's "this is basically a societal choice" reaches all the way down to how solid an individual's foothold is. A Set B strategy is simultaneously a personal strategy and a piece of policy advocacy.
Here is the cruel part, and it is the strongest form of the underclass worry. Every one of these assets can only be built by doing real work, under real risk, over real time, which is precisely the apprenticeship AI is dissolving at the bottom of the ladder.
Before: do execution → judgment develops → acquire Set B → leverage AI
After AI: AI does the execution → no experience to grow judgment → cannot acquire Set BJuniors who lean on the tools finish their tasks without ever understanding them (Anthropic research); the rung that used to convert execution into judgment is being quietly sawn off. The most valuable assets become harder to acquire at the very moment they become most valuable. So the "last chance" anxiety people describe is not really about a window for building wealth. It is about a ladder being drawn up while they are still climbing it. Those who already held Set A and Set B before the AI era can amplify them; those starting to climb now find the rungs gone. And the cross-class solidarity the article notices (white-collar and blue-collar alike) has a precise economic basis: both groups held nothing but the cognitive-execution labor that is now commoditizing.
The old ladder bundled four functions into "execution": exposure to cases, calibration of judgment against outcomes, a graduated increase in responsibility (failing safely at small stakes while climbing), and a legitimacy signal ("paid their dues"). When AI takes execution, all four are lost at once, and rebuilding means unbundling them and re-supplying each by other means. Exposure and calibration AI can actually accelerate, provided the human judges first and checks against AI second, or no calibration happens. Graduated responsibility is the hard one: AI offers no "small, safe failure," so it must be synthesized (shadow responsibility, where you record your judgment and reconcile it against the real outcome without acting on it; staged delegation; and the responsibility-insurance logic of Part 1, where insurance replaces "the boss catches it"). But because firms in the AI era cannot recapture training investment (Becker 1964), supplying graduated responsibility is a market failure, essentially a public good. The individual can self-build the first rung (the discipline of recording judgments and reconciling them with outcomes); the rest needs policy.
Reaching Set A, finally, runs through Set B. Entrepreneurship is the canonical device for converting Set B into Set A, turning trust, relationships, and a proprietary feedback loop into equity, a rent claim, and a customer base of one's own. The other conversion paths are joining an organization that pays in equity, becoming an investor or allocator, or being a deeply specialized independent professional. Compute can simply be rented; the genuinely scarce Set A items (mass distribution, energy) mostly cannot be reached except through a Set B → Set A conversion. Which is the real content of "the window is closing": it is a race between converting labor income into a rent claim and the rate at which the ladder is pulled up.
TL;DR: Automation that is rational for each firm destroys, in aggregate, its own market. The MPC gap makes "high GDP yet collapsing demand" possible. The labs sit downstream of that demand. "No policy" converges to a crash, a stable bipolarization, or a political rupture.
Parts 1–4 were microeconomics: who captures the rent. This part is macro: the cycle in which the final demand that pays that rent is eroded by AI's substitution of labor. It is the AI version of three old arguments: Marx's realization problem, Keynes's effective demand, Kalecki's capitalists' dilemma, and its kernel is the (possibly apocryphal but apt) Ford–Reuther exchange: "How are you going to get those robots to buy your cars?"
What is rational for each individual firm (automate, cut costs, raise margin) destroys, in aggregate, the demand those same firms sell into. And the top three labs can be the ultimate victims of that fallacy of composition, because their product (automation) erodes their customers' customers (consumer demand).
Layer 1: labor share ↓ + unemployment → consumer income ↓
Layer 2: discretionary consumption ↓ (necessities hold up, by Engel's law)
Layer 3: revenue ↓ at the firms that serve discretionary demand
Layer 4: enterprise AI spend is derived demand → it shrinks when final demand shrinks
Layer 5: top-three revenue ↓Enterprise AI spending exists only because companies are selling to consumers. The labs sit downstream of the very consumer demand their product is shaving away. Alex Karp put the boardroom version of it plainly: if the country comes apart, none of us make any money, the realization problem stated as a CEO's intuition.
AI does not destroy income so much as redistribute it (labor → capital, labor share down). The unemployed lose income; capital owners and AI firms gain it; aggregate income can be flat or even rise. So why does demand shrink? The gap in the marginal propensity to consume:
Worker MPC ≈ high (spends most of income)
Capital-owner MPC ≈ low (saves/invests most)
Redistribution from high-MPC to low-MPC hands ⟹ aggregate consumption falls even with aggregate income constantOutput (supply) can rise while demand for that output sags, Say's law breaking on the MPC gap. A "rich AI economy" (high GDP) and a demand collapse are perfectly compatible; that is the underconsumption core of Kalecki and Keynes. The low-MPC money that isn't consumed flows into asset markets instead, producing the divergence we already see, an asset-price boom (AI investment reported as a large share of recent GDP growth) alongside stagnant real final demand. But asset values are claims on future consumer cash flows; if consumers can't buy, those claims get marked down. It is a reflexive bubble at the macro scale.
The labs' insulation is front-loaded and their exposure is back-loaded.
| Force | Direction | Phase |
|---|---|---|
| (a) Substitution force: revenue ↓ → cut costs by deploying more AI | AI spend ↑ (counter-cyclical) | early downturn |
| (b) Scale force: output shrinks → less AI needed | AI spend ↓ (pro-cyclical) | after automation completes |
Early in a downturn the labs are protected by defensive automation; once labor has been cut to the bone, the substitution force (a) saturates, and AI spend becomes a function of shrinking output (b) alone. The pivot is "peak labor displacement," and it lines up with the wave structure of Part 2 (the insurance runs dry wave by wave).
The promise of the optimists inverts here. The hopeful story is that AI drives the price of goods down far enough that even a shrunken income still buys a decent life, abundance as liberation. Read as political economy, abundance does something colder: cheap necessities make a permanently excluded class survivable, which is to say stable rather than explosive. Bread without the circuses. On this reading abundance does not free the underclass; it is the thing that could make a permanent underclass politically durable. (Baumol qualifies it: the things that don't get cheap (housing, healthcare, positional goods) become the binding constraint on real welfare, and where they threaten survival, stability gives way to rupture.)
Could the system self-correct without policy? No, because demand is a public good. If one firm props up demand on its own, it bears the full cost while the benefit scatters across all firms, and a fully automated competitor drives it out. Propping up demand alone is competitive suicide (Kalecki's capitalists' dilemma). The wage-generated aggregate demand is a positive externality no firm internalizes. The partial exception is monopoly: a near-monopolist internalizes more of the demand externality (Ford's $5 day), so any endogenous private correction points not toward broad wage recovery but toward corporate feudalism, company-town welfare that saves a firm's own workers and no one else. Amodei's musing about paying employees who no longer add value is exactly this species, and exactly this limited.
So "no policy" resolves to one of three endpoints:
| Endpoint | Mechanism | Precedent |
|---|---|---|
| (a) Involuntary crash | Asset prices correct on unrealized demand → depression → reset by capital destruction | Marx's crisis theory; reflexive-bubble collapse |
| (b) Stable bipolarization | A small formal sector (for capitalists + B2B) plus a large excluded sector — the underclass as the equilibrium, steady not transitional | The Gilded Age, the dual economy |
| (c) Political rupture | Pressure routes into force → non-economic corrective | The article's arson; Karp's "the country explodes" |
Deflationary abundance is the selector between (b) and (c): cheap bread keeps the masses alive → stable dualism; Baumol goods threaten survival → rupture. The darkest inversion is that the promised abundance functions less as liberation than as the sedative that makes a permanent underclass politically sustainable.
I red-teamed this dark conclusion hard, and the most uncomfortable finding is that the most hopeful-looking objection makes it worse, not better. The objection runs: labor still gets employed, comparative advantage leaves low-value tasks to humans (because compute is finite), and the wealthy will pay for human service. True, perhaps, but that rewrites "explosive exclusion" into "stable low-wage subordination," a servant economy. The employed don't revolt, so it is more stable, and the labs' demand ceiling is slightly higher. Even the hope of self-correction-by-rupture gets eroded by the rebuttal. The only endogenous forces that actually break the dark equilibrium are a technological plateau or lag (does substitution complete?) and fiscal necessity (a collapsing tax base forcing the state to act before the grim fixed point is reached). Whether the first of those holds is an empirical question, and that is exactly where Part 6 turns.
TL;DR: The logic descends to a dark equilibrium, but the evidence pulls it back. Physical labor is still slow; a thin moat erodes the capital chasing it. The likeliest shape is partial substitution punctuated by financial crises, more Minsky than Marx. The reprieve is a clock, not a wall, and it keeps shrinking.
Here I stopped reasoning and met the data. The "five remaining uncertainties" reduce to three drivers, and feeding verified data into the dynamics changed where the system settles.
| Driver | Variables | Decides | Governs |
|---|---|---|---|
| A. Reach of substitution | Cognitive generalization beyond coding + the robotics lag | How much, how fast | Whether the dark dynamics of Parts 2 and 5 even fire |
| B. Durability of rent | The OSS lag + moving-frontier inference cost | Whether the top three keep a thick margin | Part 3 |
| C. Fundability | Capex vs revenue | Whether capital markets fund the race to the finish | The reflexive bubble |
A is upstream (does the dark dynamic fire), B is distribution (who takes the rent), C is the gate on the upstream (a bubble collapse stops the race).
Revenue is hump-shaped in substitution: early substitution (replacing high-cost labor while demand is intact) raises revenue; late substitution (eroding demand via the MPC gap) lowers it. There is a revenue-maximizing optimal substitution rate A*, beyond which the move is self-defeating. But by the fallacy of composition no single firm stops at A*, cost-cutting is a private benefit, demand destruction a shared cost, so the system overshoots A* and triggers a bust. The result is a Minsky-type limit cycle: boom → overshoot → demand destruction dominates → revenue falls → capital markets lose patience → bust (capex collapses, assets crater, some labs fail) → partial reset (capital destruction compresses inequality a little, rebalancing the MPC, reviving some demand) → new boom. And it ratchets: the automation capability survives each bust (a function once automated stays automated even when capex stops), so substitution drifts upward cycle over cycle, the demand floor drifts down, and the crises deepen, until the A-ceiling (the limits of substitution) stops it.
One corollary is worth stating because it reframes corporate "generosity." Redistribution moves A* outward, if you prop up demand, revenue keeps rising to a higher substitution rate, which makes a UBI funded by robots and robot-owners the industry's profit-maximizing strategy, not its charity. When AI firms talk about redistribution, that is an offensive move on the demand curve, not altruism.
Robot hardware is accelerating: the 2035 market forecast was revised up roughly sixfold, unit prices fall about 40% a year (faster than the assumed 15–20%), and real pilots run on factory floors. And the learning side has genuinely leapt: the newest manipulation models generalize to entire houses never seen in training, with a data-diversity scaling law (an ablation showed multi-environment data is load-bearing, success collapsing from 94% to 33% without it), and skills now transfer across different robot bodies with no retraining (cross-embodiment motion transfer between distinct platforms). World models supply synthetic training data. This is the closing mechanism made visible: Moravec's paradox is not a permanent law but a slope with a plotted descent.
And yet reliability is still poor. On the first large independent real-hardware benchmark, the best generalist policy completed just 17.7% of tasks (task-specific policies, 43.7%), and the home humanoids now shipping are still teleoperated by humans behind the scenes (autonomy on the order of 60–70%). Physical labor is protected for now, not because robots can't learn, but because they can't yet be trusted to be left alone. "Years to decades" reads as too comfortable; for meaningful (not total) physical capability, "years, not decades" is closer.
The commodity gap is about three months and enterprise customers switch easily; if the frontier confers little lasting advantage and customers don't stay, the capital expenditure chasing it is hard to justify. The financing is circular, a handful of giants are each other's suppliers, customers, investors, and validators, with cloud-credit investment and intertwined stakes, sitting on a duration mismatch between hardware that depreciates in about a year and debt written against a 7-to-15-year life. The leading labs are still deeply loss-making; one is reported to burn past $100 billion before turning profitable around the end of the 2020s, even as its private valuation roughly doubles every few months. None of it is audited, because these are private companies and the real margins stay behind the curtain, which is exactly why the coming run of IPOs is the keystone. An S-1 is the first document that drags the true unit economics and the circular deals into daylight. If the economics are sound and the lock-in is real, that disclosure steadies the edifice; on what's visible so far (loss-making, low-switching-cost, share that keeps changing hands), disclosure looks likelier to test the moat than to confirm it. Note the link this creates: the thin moat (B) and the bubble (C) are two sides of one coin. The same commoditization that shelters consumers is what unsettles the capital chasing the frontier.
Put these together and the system does not glide smoothly into a terminal underclass. The dark theory quietly assumed near-total displacement would arrive smoothly; but displacement eats the demand that funds the next round, the moat is too thin to justify the capex, and the physical economy isn't falling on the same timetable. So it overshoots and corrects, boom and bust, more Minsky than Marx. The most likely shape is perpetual partial substitution broken up by financial crises, the first of which is probably financial and not far off, with the ceiling on displacement sitting well short of "everything."
In honesty, this "first crisis is financial" call is also the least confident prediction in the report. The core of the driver it rests on (Driver C, the frontier labs' unit economics) failed verification both times it was tested (Appendix A). The timing and scale of the correction are inferred from the fragility of the financing structure, not from settled numbers. What is solid is the fragility; when and how large the break is remains the shakiest part of the whole analysis.
That is not good news so much as less catastrophic news. White-collar workers in the most calculable, most verifiable domains (coding, routine analysis) still take a real hit, and a financial correction does its own damage. Amodei's "white-collar bloodbath" has the evidence behind it; refined by the data, it reads less as wholesale replacement than as augmentation-driven headcount reduction, humans orchestrating while AI does expert-quality subtasks, with fewer people per unit of output. But a total, frozen, permanent underclass is not on any near trajectory.
Why the reprieve exists is worth stating carefully, because the glib version is wrong. It is not that AI turned out weaker than advertised. In both cognition and the physical world the generalization machinery is plainly working, language agents now produce expert-grade knowledge work beyond coding (quality approaching human experts), robots now generalize across homes and bodies. What is missing in both is autonomy and reliability: the agent that writes a strong deliverable still can't be trusted to run the whole multi-step job unsupervised; the robot that generalizes still fails most of what you hand it. And reliability, in both cases, sits on a scaling curve, not against a wall. So the most honest sentence is also the least reassuring: the reprieve is a clock, not a wall. The machines are good enough to do the work but not yet reliable enough to be left alone with it, and "not yet" keeps shrinking. The near-term attractor is unchanged (the Minsky cycle); the medium-term displacement ceiling has been revised up.
TL;DR: Resilience and reward point in opposite directions. The highest-paid white-collar work is the most fragile; low-wage interpersonal and physical work is the strongest. Some roles (e.g., radiology) are "high pay but capability rent" traps. Inside organizations, the middle disappears. Detailed scores follow.
I scored the resilience of industries and roles on six axes (1–5 each, 30 total), and additionally assessed reward on two axes: the level of reward P and the durability of reward D. D asks what the wage is a rent on. A rent on capability vanishes; a rent on supply restriction or legitimacy persists. This is the job-survival-versus-wage-survival distinction from Part 1, made operational.
Table 8, Resilience scores for major industry sectors (six axes, 30 total)
| Sector | Total | Type of wall |
|---|---|---|
| Healthcare (surgery, emergency, procedures) | 28 | Both walls (strongest) |
| Public safety | 27 | Both walls |
| Care / welfare | 26 | Both walls |
| Law (trial, negotiation) | 24 | Social (license + responsibility) |
| Skilled trades (electrical, plumbing) | 23 | Capability (physical) |
| Education (interpersonal) | 22 | Social (relationships) |
| Construction / civil engineering | 21 | Capability (physical) |
| Healthcare (diagnosis, reading) | 20 | Social (license + risk) |
| Professional services (audit) | 16 | Social (license only) |
| Law (contract, routine) | 13 | Weak / Wave 2 |
| Finance (analysis, underwriting) | 11 | Weak / front of Wave 2 |
| Software / IT | 9 | Almost none / Waves 1–2 |
An uncomfortable ordering emerges. The highly-educated white-collar is the most fragile, and the low-wage interpersonal and physical work is the strongest. Resilience and reward point in opposite directions.
Even within one industry, resilience splits by role. There are "trap" roles where the reward level P is high but the durability D is low.
Table 9, Decomposing the professions (R resilience / P reward / D durability)
| Role | R | P | D | Verdict |
|---|---|---|---|---|
| Surgeon / invasive procedures | 28 | 5 | 5 | The golden intersection |
| Emergency / intensive care | 27 | 5 | 5 | The golden intersection |
| Trial advocacy | 24 | 5 | 4 | Strong |
| Nursing (ward) | 25 | 3 | 4 | High resilience, mid reward |
| Reading / pathology | 18 | 5 | 2 | Trap (high pay but capability rent) |
| Contract law | 13 | 4 | 2 | Trap |
| Care worker | 26 | 1 | 3 | Highest resilience, lowest reward |
Physicians who work with their hands (surgery, emergency) score 5 on both P and D, but physicians who read images (radiology, pathology) score 5 on P and only 2 on D. The high pay is an illusion of durability. Once AI catches up on reading quality, what remains is the "theater of responsibility", a license holder signing off.
The bulk of employment is white-collar work at operating companies. Cut by function rather than industry, the outline sharpens.
Table 10, Functional assessment at an operating company (R / P / D)
| Function | R | P | D | Verdict |
|---|---|---|---|---|
| Accounting / HR / general affairs | 8–9 | 2 | 1 | Direct hit |
| Inside sales | 9 | 2 | 1 | Direct hit |
| Consulting / IB analyst | 8–9 | 3–5 | 1 | The biggest trap |
| Enterprise sales (relationship-building) | 18 | 4 | 4 | The golden intersection |
| Production engineering / maintenance | 19–20 | 3 | 4 | A solid fortress |
| Senior management / partner | 16–18 | 4–5 | 3–4 | Survives, but a select few |
For the ordinary employee the biggest risk is not unemployment but the disappearance of the middle. In every function, the juniors who do the hands-on work take a direct hit while the seniors who carry responsibility and relationships remain. But once the juniors are gone, the path to growing seniors is severed too. Organizations reorganize around a few seniors plus AI, and the chairs for middle managers and new hires are lost in bulk. The barbell-ization of the labor market shows up, inside the organization, as flattening.
The type of wall sets the shelf life. Physically protected work is strong now, but its clock begins to move in the back half of a ten-year span, and Finding 1 showed that clock now has a plotted descent. Legitimacy-protected work persists unless society chooses not to entrust it to AI.
Table 11, The four waves of erosion
| Wave | Timing | Rate-limiter | Affected |
|---|---|---|---|
| Wave 0 | –2028 | Calculability thin | General clerical, CS, analysts |
| Wave 1 | 2027–2030 | Falls once autonomy arrives | Contract law, audit, reading, analysis |
| Wave 2 | 2030–2035 | The physical wall begins to erode | Factories, warehouses, delivery, routine construction |
| Wave 3 | 2035–, indefinite | Legitimacy (society won't entrust it) | Surgery, care, the courtroom, interpersonal education, senior responsibility |
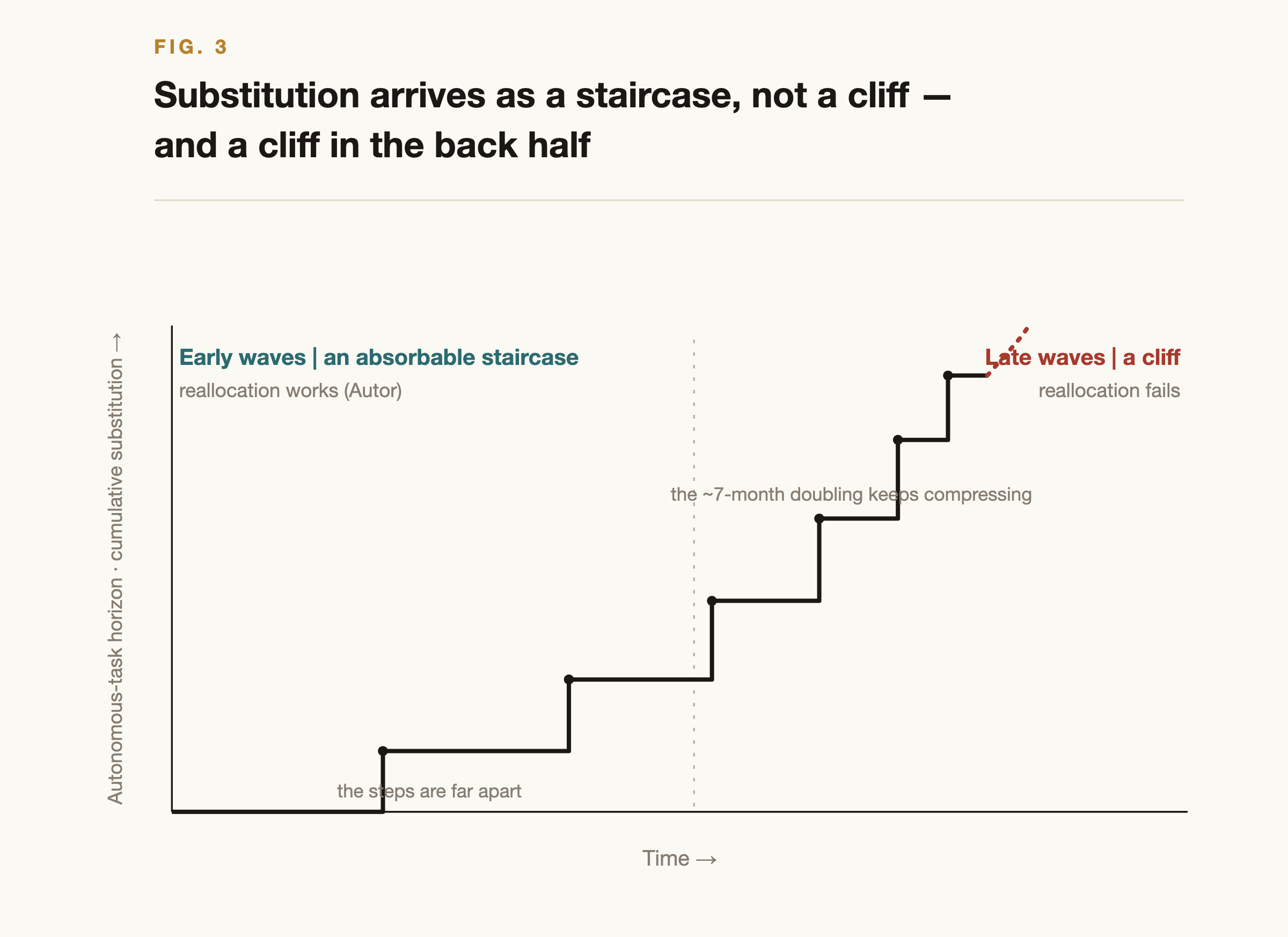
Figure 3, The staircase of substitution. Each time the horizon crosses a threshold, a band of roles falls at once; as the doubling clock shrinks, the back half approaches a cliff. The optimists are right early, the pessimists right late.
The physical fortress is a short-term refuge; the legitimacy fortress is a permanent home.
TL;DR: What is born is the two ends of the barbell, a few AI specialists and the low-wage frontline roles that grow most in number. The clerical middle vanishes. The most durable new roles are in responsibility and assurance, which the EU AI Act is creating as law.
I checked the jobs being born against primary sources.
Table 12, Verification data on jobs and industries being born (primary sources, 3-vote check)
| Claim | Verification data | Source |
|---|---|---|
| Net job gain | 170M created and 92M displaced by 2030, net +78M. The net gain specific to AI / information technology is about 10M | WEF Future of Jobs 2025 |
| Fastest growth rates | Big data ~110%, fintech ~95%, AI/ML ~85% | Same |
| Largest absolute growth | Frontline roles — agriculture, delivery, care (not tech roles) | Same |
| Usage in practice | Consumer-facing Claude.ai skews toward augmentation but wavers; enterprise and API skew toward automation (about three-quarters to 97%) | Anthropic Economic Index |
| Regulation-driven demand | EU AI Act Article 4 (AI-literacy obligation, in force February 2025, legally binding) | EU AI Act official |
| The provenance standard | C2PA is a multi-party standard under the Linux Foundation (Adobe, Microsoft, Google, OpenAI, and others) | C2PA official |
What is born is the two ends of the barbell: the AI specialists who lead on growth rate (few in number) and the frontline roles that grow most in absolute terms (low in wage). The clerical middle disappears. The most durable new roles are in the territory of responsibility and assurance, and the EU's AI Act is creating these as a matter of law, one of the few cases where the theory is corroborated by a regulatory implementation rather than by forecast.
Worth flagging: automation already dominates in the enterprise, and the augmentation skew is only the picture when you crop to consumer use. Do not misread "AI is an assistant for now" as permanent safety: that is reading a transitional state as a terminal one.
TL;DR: New demand clusters in the complement of what AI commoditized, trust, responsibility, relationships, meaning. The business sweet spot is the accountability and assurance that regulation guarantees. The agent economy's payments and standards are already held by incumbents. Detailed scores follow.
Parts 1–8 looked at the supply side, occupations, labor categories. This part shifts to the demand side, using Christensen's Jobs-To-Be-Done: what progress people, organizations, and AI agents will newly want to hire for. Occupations are supply-side labor; JTBD are demand-side progress.
AI changes the jobs to be done in three ways:
| Mechanism | What happens | Example |
|---|---|---|
| ① Collapse | AI zeroes out a functional job → it stops being hired and becomes ambient | You no longer hire a translator |
| ② Elevation | The functional layer falls, a meta-job appears one level up | Not "someone who writes" but "someone who decides what is worth writing and vouches it is true" |
| ③ Emergence | A situation that never existed before generates a genuinely new job | "I ran ten agents overnight — I want to know it was done right" |
The unifying principle: every new JTBD clusters around the legitimacy moats of Part 4 (trust, accountability, relationships, meaning) because those are the emotional and social dimensions that turn scarce exactly as AI commoditizes the functional one. The supply-side legitimacy moat and the demand-side new JTBD are the same coin from two sides.
This resolves a tension. In Part 4, taste was the weakest complementary asset to sell as a skill. But on the demand side it inverts: the job "filter the infinite AI output for me" grows strongly. Selling your taste as a skill is weak; serving the hunger that taste-scarcity creates is strong. Likewise the meaning job, when AI makes achievement free, people pay to feel they did it themselves (the Strava/Duolingo/handmade pattern); effort itself becomes a scarce good.
The least-explored layer is the one where AI agents themselves begin to hire. They hire tools and APIs (tool discovery, settling payment, trusting outputs: agentic payments). They hire other agents (delegating subtasks, verifying each other's work, establishing reputation and identity, resolving disputes: the A2A infrastructure). And, in the deepest inversion, agents hire humans, for the physical last mile they cannot do, the accountability they cannot hold, the legitimacy they cannot borrow. That is the hopeful reversal of the underclass thesis: not "AI takes human work," but a demand in which AI hires the human it cannot itself be. The primitive first form already exists (humans hired to train AI); the mature form is a market where agents hire humans on demand for regulatory sign-off, physical execution, and interpersonal assurance. The entire institutional layer that human society took millennia to build (identity, reputation, trust, payment, verification, dispute resolution) is what the agent economy will need in a few years.
I enumerated these intersections as 24 business options and scored them on four axes: demand strength J, moat buildability M, market size, and actor fit (S = startup, E = incumbent, B = both).
Table 13, Scores for major business options (J + M + market, 15 total)
| Business | J | M | Market | Fit | Total |
|---|---|---|---|---|---|
| A2A payments | 5 | 5 | 5 | E | 15 → revised 12 |
| AI insurance / liability underwriting | 5 | 5 | 4 | E | 14 |
| Agent ID / reputation | 5 | 5 | 4 | S | 14 → revised 12 |
| AI audit platform | 5 | 4 | 4 | B | 13 |
| Domain-specific AI assurance | 5 | 5 | 3 | S | 13 |
| A marketplace where AI hires humans | 5 | 4 | 4 | S | 13 |
The top band clustered into two: the accountability domain where regulation creates demand, and the infrastructure of the agent economy.
Verifying these two against real companies, funding, and standards forced a clear revision.
Table 14, Empirical check on the business options
| Cluster | Reality | Winner |
|---|---|---|
| AI insurance | Munich Re aiSure (since 2018, covers hallucination), Armilla (an MGA model riding Lloyd's underwriting capacity) | Incumbent capacity × startup product design |
| AI audit | Credo AI (raised over $40M, Mastercard a customer), Holistic AI | Startup-led |
| A2A payments | Google AP2, Stripe / OpenAI's ACP, Visa, Mastercard control the standards | The incumbents |
| Agent ID | Incumbents like Okta entering; no independent startup confirmed | Tilts to incumbents |
The conclusion was clear. The payments and standards of the agent economy are already being seized by Google, Stripe, Visa, and Mastercard. This is the payments version of the market-structure chapter's point: the true competitor is the distribution platform, and the incumbent integrates forward. What is left for startups is the accountability / assurance domain where regulation guarantees the demand, and the empirical detail is worth being precise about. AI insurance is already live and working: Munich Re's aiSure has covered hallucination and AI error since 2018 (covering, not excluding), and Armilla writes affirmative AI-liability cover on Lloyd's capacity with an underperformance trigger. The structure is exactly the one the discussion predicted: the incumbent supplies the capacity, the startup supplies the AI-specialized product design and distribution, the MGA (managing general agent) model. AI audit is well-funded and startup-led (Credo AI has raised over $40M with Mastercard as a customer). And the demand is legally time-stamped, not speculative: the EU AI Act's high-risk obligations and the AI Office's enforcement powers phase in through 2026–2027.
Generalize the finding and AI businesses form a layer cake, with incumbent-held and startup-held layers alternating:
┌─ Application / vertical layer ──── startups win (thin but many)
├─ Standards / protocol layer ────── incumbents (AP2 / ACP / MCP) ← taken
├─ Rails / payments / ID layer ───── incumbents (Visa / Stripe / Okta) ← taken
├─ Regulatory-assurance / insurance ─ startup + incumbent hybrid (the A cluster) ← remains
└─ Model layer ───────────────────── the top three (Part 3)Incumbents hold the horizontal standards and rails; startups remain in the vertically specialized apps and the assurance that regulation requires. The assurance layer stays open to startups precisely because it is split vertically by regulation and domain, demands actuarial/audit expertise, and finds incumbents (insurers, the Big Four) holding capacity and brand but not AI-specialized product design. This is the business-level form of Part 4: startups lose on distribution and capital but win on proprietary data and domain trust.
Three spaces remain for startups. First, vertical apps on top of incumbent rails: the payment standard is taken, but implementing agent commerce for a specific industry (medical procurement, construction materials, B2B wholesale) on top of it is not; the value is industry knowledge and compliance. Second, the MGA model: the startup carries no capital, riding incumbent insurance capacity while owning the AI-specialized underwriting and distribution; an MGA for a specific AI risk (medical, legal, autonomous agents) is "the tap on AI adoption." Third, vertical regulated-assurance specialists: once the EU AI Act regulates a high-risk domain, each domain (medical, hiring, credit, education) needs its AI audited and assured by a specialist; horizontal audit raised the money, but vertical specialization stays with startups.
The traps to avoid are the mirror image: competing on horizontal infrastructure (payments, ID, orchestration standards, already incumbent-held), ambitions to be "the OS of the agent economy" (MCP/AP2 are top-three standards you'd be parasitic on), competing on model performance (you lose to the top three), and post-regulation compliance SaaS (commoditizes). The winning formula:
Win = vertical specialization (a narrow domain) × regulation-guaranteed demand (J assured) × expertise incumbents lack (actuarial / clinical / legal), and do not compete on horizontal infrastructure, standards, or the model.
This is the convergence point of the whole analysis: the best opportunity is neither "building AI" nor "AI infrastructure" but absorbing the assurance, insurance, and responsibility that society demands as law when AI enters regulated, high-risk domains. Part 1 (the insurability of responsibility) → Part 4 (the legitimacy moat) → Part 8 (regulation-driven new roles) → the empirical check here (Armilla, Credo AI are real) all point to the same place. It is a third answer, grounded in evidence, distinct from both the booster's ("the next unicorn is the app layer") and the doomer's ("the top three take everything").
TL;DR: AI grows the pie as well as substitutes, but the effect differs by orders of magnitude, 200x in computation, 0.2% in the physical (an Amdahl's law for science). New GDP does come, but on the 10-to-15-year timeline of the physical and the clinical, not the media's.
The analysis so far has implicitly run on the frame "AI = automating existing tasks (substitution and cost reduction)." But AI has another route.
Table 15, Three routes for the AI economy
| Route | Effect | Action on GDP |
|---|---|---|
| Substitution type | Automates existing labor | Cost reduction, demand erosion (contracts) |
| Discovery type | Makes possible what is now impossible | New goods, lifting of supply constraints (expands) |
| Transaction-cost type | Enables transactions that never closed | Surfacing of dormant demand (expands) |
Deep tech (drug discovery, fusion, materials) is the stage for the discovery type. Technical risk dominates, and AI can compress its resolution through parallel loops of trial and verification. This direction is correct, and it accurately picks out what the substitution-type analysis missed. But the degree of effect differs by orders of magnitude across domains.
The key is how much of the verification loop closes inside computation. If verification runs through the physical, then no matter how fast the computation, the whole is bound by the physical. An Amdahl's law for science.
Table 16, Ordering of deep-tech domains (search space S / computational closure I / data D / physical-loop speed P / regulatory lightness R, 25 total)
| Domain | Total | Rate-limiter |
|---|---|---|
| Protein design / structure | 23 | Almost none |
| Materials science (catalysts, batteries) | 19 | Synthesis, evaluation |
| Chemical synthesis | 19 | Automated synthesis lab |
| Drug discovery (preclinical) | 18 | Cell and animal experiments |
| Semiconductor design | 18 | Manufacturing (fab) extremely costly |
| Fusion | 13 | Building real machines, material irradiation |
| Space / launch | 12 | Physical launch, capital |
| Drug discovery (full clinical) | 11 | Clinical trials, regulation |
Surprisingly, the flashy domains the media hype (fusion, new drugs, space) carry incompressible rate-limiters, the physical, the clinical, capital. The unglamorous domains (proteins, materials, catalysts) close inside computation, and AI works well. The deep tech where AI truly works points the opposite way from the attention.
Table 17, The real numbers of an Amdahl's law for science (primary sources, 3-vote check)
| Stage | Data | Source |
|---|---|---|
| Compression on the compute side | AlphaFold's database went from 360k to 200M structures (200x) | DeepMind / EMBL-EBI |
| Compression on the compute side | GNoME predicted 380k stable materials (an order-of-magnitude expansion from the ~48k known) | Nature 2023 |
| Collapse on the physical side | Of GNoME's 380k predictions, 736 were experimentally realized (0.2%) | Same |
| The drug-discovery rate-limiter | $1–2.6B per drug, 10–15 years. Most of it is clinical. No evidence AI raised the clinical success rate | Industry data |
| Fusion | AI learned to control existing tokamaks. The rate-limiter of building the real machine is unchanged | Nature 2022 |
AI's effect on deep tech is 200x in computation and 0.2% in the physical. This two-to-three-order gap is the real number of an Amdahl's law for science. AI expands the "pie of the possible" explosively, but the speed at which it turns into a "pie of realized GDP" is bound by the speed of the physical-world loop. New GDP does come. But not at the speed the media expects (fusion and new drugs ripening all at once within a few years), it comes on the timeline of the physical, the clinical, and the regulatory: 10 to 15 years.
Even without deep tech, AI grows the pie by erasing transaction costs, reaching layers that services never reached before. Generative-AI tutoring in Nigeria produced a 0.3-standard-deviation learning gain in six weeks (the top 20% of interventions in the developing world). Kenya's Jacaranda delivers AI triage to 3 million mothers at $0.74 per person over a lifetime. This is not substitution but net addition, and it reaches the bottom. The most equalizing pie creation of all, and the bridge to Part 11.
In the macro aggregate, though, every credible estimate attributes most of the GDP effect to productivity (cost reduction) and treats new demand only as an uncertain upside. Acemoglu's conservative TFP estimate is 0.66% or less over ten years. The "trillions" in the headlines are productivity, not new demand.
TL;DR: Whether the picture is pessimistic or optimistic is a question of which metric you choose. Rent → pessimistic, GDP → neutral, benefit (consumer surplus) → optimistic. Roughly 93% of the value lives outside rent, on the benefit side.
The analysis so far has leaned structurally toward pessimism. Deliberately enumerating the positive scenarios, not as a wish-list but by collecting the seeds of hope scattered across the earlier parts and rating each by its condition, confidence, and scale, the logic that breaks the dark conclusion comes down to four routes, and within them fourteen concrete scenarios.
Dark conclusion = substitution erodes demand × rent concentrates × distribution doesn't improve
Four ways to break it:
P1 Substitution never completes (technical/physical limits) → labor remains
P2 The pie outruns the distribution problem (growth is overwhelming) → everyone richer
P3 Rent disperses (concentration breaks) → distribution improves
P4 Non-market value grows (welfare outside GDP) → a different abundanceTable 18a, P1: Substitution never completes
| Scenario | Condition | Confidence | Scale |
|---|---|---|---|
| P1a Capability plateau | Scaling stalls → augmentation equilibrium | Low (evidence denies it) | Large |
| P1b An Amdahl's law for science | Physical/regulatory rate-limiters (Part 10, 0.2% realized) → transition time | Medium–high (empirical) | Medium |
| P1c The comparative-advantage floor | Finite compute leaves low-value tasks to humans | Medium | Medium (low wage) |
| P1d The regulatory / legitimacy wall | Society won't entrust it to AI (the legitimacy moat) | Medium–high | Medium |
Table 18b, P2: The pie outruns distribution
| Scenario | Condition | Confidence | Scale |
|---|---|---|---|
| P2a Deflationary abundance | Price collapse > income collapse | Medium (Baumol goods bind) | Large |
| P2b Discovery-type TFP explosion | In-silico new goods realized | Medium (slow, physical rate-limiter) | Large (long run) |
| P2c New services to the underserved | Transaction costs vanish → the priced-out | High (empirical, most equalizing) | Medium–large |
Table 18c, P3: Rent disperses
| Scenario | Condition | Confidence | Scale |
|---|---|---|---|
| P3a The open-weight floor | OSS tracks the frontier (~3 months) → access to capability equalizes | High (empirical) | Medium |
| P3b A capital-market bust | The bubble bursts → capital destruction compresses inequality | Medium (a cruel form) | Medium |
| P3c Public wealth fund / redistribution | Policy intervention | Low (depends on politics) | Large |
| P3d AI hires humans | AI hires humans for the legitimacy moat → new labor demand | Medium (immature) | Medium |
Table 18d, P4: Non-market value grows (welfare outside GDP)
| Scenario | Condition | Confidence | Scale |
|---|---|---|---|
| P4a Liberated time | Work hours fall → leisure, creation | Medium (depends on distribution) | Large |
| P4b Democratized knowledge / education | Everyone reaches expertise → human-capital lift | High (empirical) | Large |
| P4c Cognitive augmentation / creativity | AI augments the individual | Medium–high | Large |
| P4d Scientific progress itself | Disease, climate, energy | Medium (slow, physical rate-limiter) | Very large (long run) |
The empirically grounded, high-confidence positives (the ★ band) are P2c (new services to the underserved, the most equalizing), P4b (democratized education, the consumer-surplus explosion), P1b (the Amdahl's-law transition time), and P3a (the open-weight floor, equalized access to capability). Mapped on confidence against scale:
scale: large
P2a abundance │ P4b education★ P4d science
P3c redistrib │ P2c underserved★ P4a freed time
─────────────┼────────────────────── confidence →
P1a plateau │ P1b Amdahl★ P3a OSS floor★
│ P1d legitimacy P3d AI-hires-human
scale: small (★ = empirically grounded, high confidence)The strongest claim of this report is here. The pessimism so far was almost entirely the result of measuring by a single metric, the distribution of excess profit (rent). Change the metric and the picture changes.
This rests on verified facts.
Table 19, Verification data for the "benefit" metric (primary sources, 3-vote check)
| Claim | Data | Source |
|---|---|---|
| Most of the benefit goes to consumers | Of the social benefit of technological innovation, producers capture about 2.2%; the remaining ~97.8% flows to consumers and society (1948–2001) | Nordhaus, NBER w10433 |
| AI's consumer surplus dwarfs its rent | US generative-AI consumer surplus is $116B (2025) to $172B (2026), against US AI revenue of about $7B — a ratio of roughly 14 to 1 | Stanford Digital Economy Lab 2026 |
| It doesn't show up in GDP | This benefit arises before it appears in productivity or GDP statistics (the paper's explicit statement) | Same |
| It is widely dispersed | ChatGPT reached roughly 10% of the world's adults by mid-2025, and the majority of use was outside of work | Stanford HAI 2026 |
| Precedent in free digital goods | By the GDP-B estimate, $2.52T across 13 countries (equivalent to 5.95% of GDP) | NBER w25695 / PNAS 2019 |
Three metrics give three conclusions. And every one of them is correct.
Table 20, Three metrics, three conclusions
| Metric | Conclusion | Why |
|---|---|---|
| Rent (wealth) | Pessimistic | Concentrates in capital and platforms |
| GDP | Neutral | It grows, but productivity-led, and labor's share falls |
| Benefit (consumer surplus) | Optimistic | Free AI delivers expertise, education, health, and creativity to billions |
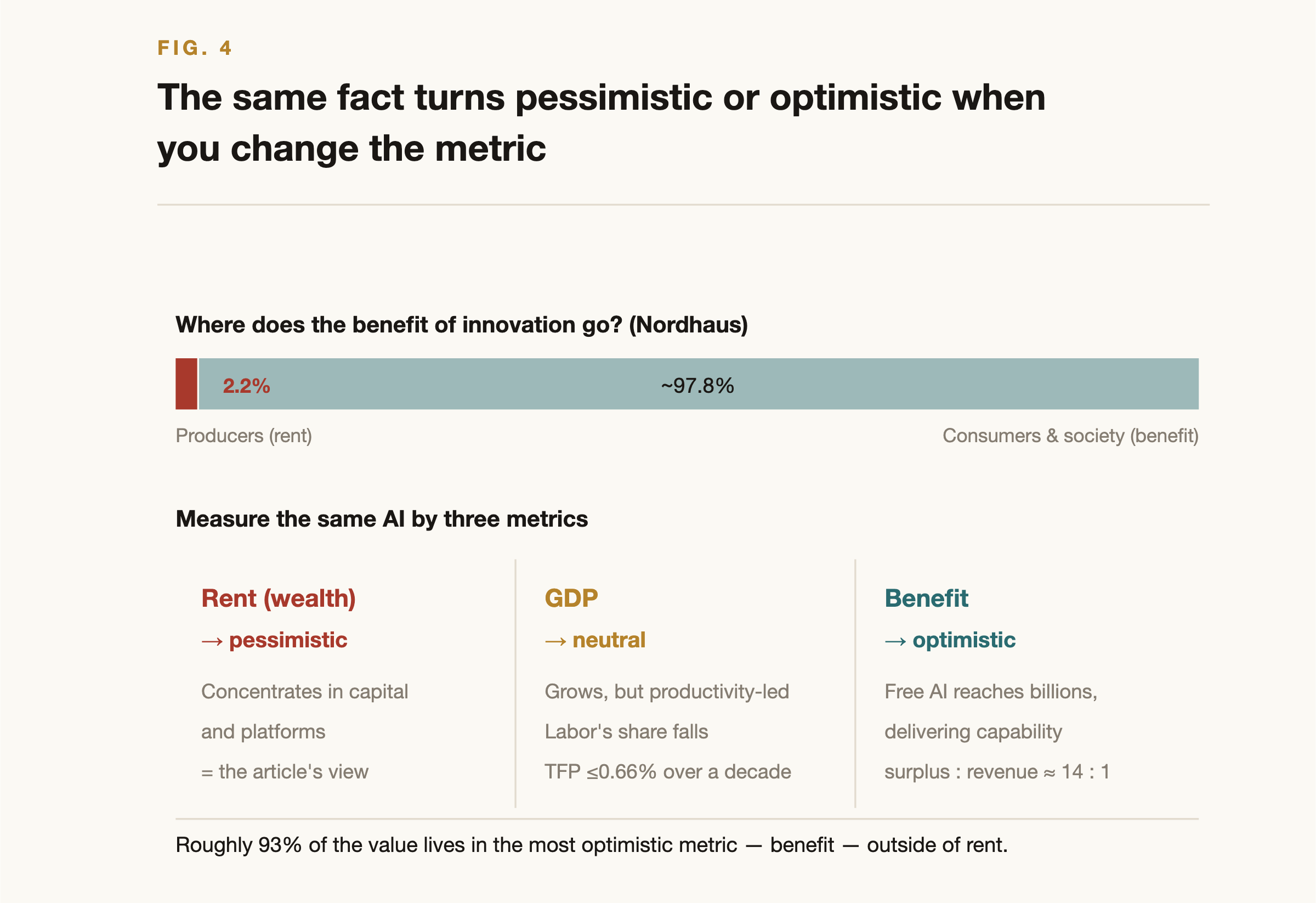
Figure 4, The distribution of value and the three metrics. About 97.8% of the benefit flows to consumers and society, and the three metrics, rent (pessimistic), GDP (neutral), benefit (optimistic), give three conclusions.
AI concentrates rent, lifts GDP gently, and explodes consumer surplus. It does all three at once. And roughly 93% of the value lives in the most optimistic metric (benefit) outside of rent.
To be explicit about where the "93%" comes from: it is an AI-specific figure, derived from the roughly 14-to-1 ratio of US generative-AI consumer surplus to revenue (Table 19). Treat total benefit as surplus plus revenue, and revenue (the rent) is one-fifteenth, about 7%, leaving fourteen-fifteenths, roughly 93%, as consumer and social benefit. Nordhaus's "2.2% to producers, 97.8% to consumers" is a different number (the historical split for innovation in general) included as a corroborating analog that points the same way, not summed into a single ratio with it. The 93% is, in effect, AI's version of that 97.8%.
A few things follow, depending on where you sit.
If you are deciding where to stand professionally: do not try to out-compete cheap cognition, and do not over-invest in "taste" or raw judgment, which is where the models are climbing fastest. Put the weight on the legitimacy assets, accountability, trust built through time spent exposed to risk, genuine relationships, and on converting those into ownership: equity, a proprietary feedback loop, customers of your own. Access to intelligence won't set you apart, because everyone will have it. What you pair it with will. And start now, while the machines still need you in the loop, because the assets that survive take years of risk-exposed work to build.
If you are reading the macro picture: plan for volatility, not apocalypse. The underpriced risk is not mass permanent unemployment; it is a financial correction in an over-leveraged, circularly financed build-out (the IPO disclosures are the thing to watch) alongside a hard squeeze on early-career knowledge workers in the most automatable fields. Treat this augmentation era as a window, and resist reading "AI can't fully do this yet" as "AI won't."
If you are building this: notice that redistribution here is not charity. Because the labs sit downstream of consumer demand, propping that demand up is the profit-maximizing move: it raises the level of displacement reachable before the industry starts eating its own market. "Automate the worker, then make sure someone can still afford the output" is, on the arithmetic, the optimal strategy, not generosity. The companies warning about an underclass while building toward it aren't necessarily hypocrites; they are describing a problem already visible in their own revenue line, and have not yet decided whether they intend to solve it.
The New York Times's underclass thesis is correct on the rent metric. Economic power (wealth) concentrates. But seen through the "benefit" metric, the picture is the opposite: "the era in which more people than ever can reach for expert-grade capability."
The most honest positive scenario comes not from hunting for optimistic facts but from choosing the right metric. Material abundance and access to capability become more equal: that is the benefit side. Economic power concentrates: that is the rent side. The two do not contradict; they happen at once. Quality of life can rise even as rent concentrates and labor's share falls.
"Does AI grow the pie?" and "Does AI save the underclass?" are different questions. The pie grows. But the underclass is a distribution problem, decided not by the size of the pie but by labor's share and where the rent goes. Discovery-type AI lifts GDP, but that GDP flows to whoever holds capital, platforms, and regulation. The expansion of the pie saves "growth," not "distribution."
What the article saw was just one-fifteenth of the total value, and the most concentrated fifteenth at that. The remaining fourteen-fifteenths is scattered across the billions of people using AI for free, and does not even show up in GDP. The article was right to be pessimistic, and at the same time it missed a great deal.
Where we are heading is a future split in two: access to capability more equal than ever, wealth more concentrated than ever. Which face you see depends on which metric you measure by.
One caveat. This "split future" is, for now, a near-to-medium-term picture. Because the reprieve is a clock and not a wall, in the long run, once autonomy and reliability have risen far enough, the distribution problem of Part 5 returns to the foreground. The benefit side still holds then (access to capability keeps equalizing; the split in metrics is durable), but the concentration of wealth can deepen further. So this is not a license to relax about the long run; it makes the question of how to handle distribution before the clock runs out more urgent, not less.
And the largest contest of the politics and policy ahead will probably be how to handle that split itself.
This report was built from the April 2026 New York Times opinion piece, reasoning one step at a time within economic frameworks, then putting that reasoning through a multi-stage verification against primary sources. Verification used a generative-AI research harness across 17 runs in total. Each run consisted of roughly 100 search agents, about 25 primary sources, and a 3-vote fact-check. Claims that did not pass (several well-known bubble statistics, model-collapse claims, particular companies' margin figures, the specific requirements of ISO 42001, the funding sizes of some startups) were removed from the text. Notably, the frontier labs' specific unit economics failed verification twice in a row, which is why the report describes the financing structure as fragile rather than declaring a bubble outright (see Appendix A).
There is an asymmetry: emerging areas have thin primary data and are a notch less certain than the disappearing jobs (which can be measured directly in falling job postings). This is made explicit in the text. All figures are as of mid-2026 and rest on primary sources including Epoch AI, METR, the World Economic Forum, the EU AI Act, Stanford's Digital Economy Lab, the NBER, and papers published in Nature. Where the data is contested or unaudited, that is noted.
This inquiry resolved five conceptual questions (the durability ranking within Set B, rebuilding the ladder, reaching Set A, the scaling plateau, the synchrony of timing) and folded them into the body above. But the empirical variables that decide the fate of the conclusion remain genuinely open. This appendix names them, says why each matters and what would move it, so that the conclusion (especially the final attractor of Part 6) can be recalibrated as new data arrives. They are the constituent parts of the three drivers (A reach of substitution, B durability of rent, C fundability).
Table A1, The five variables that hold the conclusion's fate
| # | Variable | Current state | Why it matters | Recalibration trigger |
|---|---|---|---|---|
| #1 | The OSS ↔ closed-frontier lag (its trend in months) | ~3–3.5 months, non-monotonic (90% CI 1.1–5.3); but 8–10 months on private/agentic benchmarks | Driver B. The decision variable between Part 3's telecom (stable oligopoly) and Linux (commoditization) | A clean quarterly time series of the gap; the newest open weights getting scored (currently possibly understated) |
| #2 | Whether METR's agentic horizon generalizes beyond coding/ML | Resolved (most pivotal): does not generalize uniformly — linear (not exponential) outside coding, autonomy capped ~30%, visual computer-use 40–100x behind; but quality approaches human experts (GDPval-AA Elo 1890) | Driver A (cognitive). Gates whether the dark dynamics of Parts 2 and 5 fire at all. If it doesn't generalize, the augmentation equilibrium — the only antidote to the dark conclusion — holds | This is the calculability clock restated; track METR's non-coding domains and real-world agentic failure rates as proxies |
| #3 | How fast robotics catches up to physical labor (the Moravec lag) | Closing mechanism now visible (home generalization, data-diversity scaling law, cross-embodiment) but still wide: 17.7% on the first independent real-hardware benchmark, home humanoids teleoperated | Driver A (physical). The height of the A-ceiling. If physical is slow, the cycle stabilizes (the second antidote) | Manipulation generalization approaching an operational threshold (~99%+); a humanoid showing net labor substitution rather than R&D / training-data generation |
| #4 | Whether AI capex outruns revenue (capital markets' patience) | Unresolved (the hole persists). Margins, burn, break-even failed verification twice; the structural case (circular financing + duration mismatch) is documented, the bubble verdict contested | Driver C. The core of "the first bust is financial." Sets the amplitude and period of the A↔C cycle | The frontier labs' verifiable gross margin / capex-to-revenue growth / FCF coverage on disclosure; the depreciation schedule; the first large default or write-down |
| #5 | The moving frontier's per-answer inference cost | Resolved: per-task cost is rising (~3–18x/year) as reasoning consumes tokens (o3-high ~$3000/task), while fixed-capability cost falls (~50x/year per token) | Driver B. The economics of the frontier premium; whether reasoning-model economics favor concentration or dispersion | A per-task total-cost time series (unit price × token consumption) for the same frontier task |
The driver map and the fatal interactions:
A (reach of substitution) = #2 + #3 → does the dark dynamic fire
B (durability of rent) = #1 + #5 → who takes the rent
C (fundability) = #4 → does the race reach the finish (the upstream gate)
Fatal interaction: A's success destroys C (substitution kills demand, demand kills revenue, revenue kills capex)
New link: a thin B (OSS ~3 months) erodes C (no moat → capex unjustifiable)Three new watch-items emerged from the latest research and deserve standing attention: whether the gated frontier (Project Glasswing) is a permanent moat or temporary safety (if permanent, B strengthens and top-of-stack inequality becomes structural); the progress of the manipulation scaling law (how far generalist success climbs from 17.7% as the number of training homes grows, i.e., the rate at which the physical antidote expires); and the frontier labs' IPO / S-1 disclosure (the resolving event for #4, the single observation point that judges B and C at once).
Monitoring priority, in order: #2 (most pivotal, least directly researchable, track non-coding agentic failure rates as a proxy); #4 (sets the timing of the first bust, the most near-term observable event); #3 (the height of the A-ceiling); then #1 and #5 (they decide distribution but not the shape of the attractor).
Parts 1–2 (responsibility, the speed of substitution). Coase / Calabresi (1970), the least-cost avoider, tort law converges on "who can bear the cost most cheaply." Elish (2019), the moral crumple zone, the human is kept as a buffer that absorbs blame, not for safety. Parasuraman & Riley (1997), automation complacency, the more accurate the system, the more people stop verifying. Kleiner & Krueger (2013), occupational licensing, a license is a supply restriction that generates rent (what protects the wage is the license, not the responsibility). Becker (1964), general human capital, training benefits spill over, so individual firms can't recoup them (the market failure behind the hollowed ladder). The Jevons paradox, efficiency raises total demand (radiology; Hinton's 2016 "no more radiologists" prediction that failed). Korinek (all occupations vulnerable) versus Autor (new industries created), the comparative-advantage debate. Frey (2019), The Technology Trap, "the short run can be a lifetime."
Part 3 (market structure). The folk theorem, fewer players sustain tacit coordination. Cournot versus Bertrand, capacity competition (positive margin) versus price competition (zero margin). Christensen, low-end disruption (Unix → Linux) and the conservation of attractive profits (commoditization moves profit to the adjacent layer). Spolsky, "commoditize your complement" (Meta/Llama's motive). Ben Thompson, aggregation theory (when supply is free, demand-side aggregation goes winner-take-most). Soros, reflexivity (the two-directionality of speculative-demand Jevons).
Part 4 (complementary assets). Varian, the principle of complements (be a complement to what gets cheap, not a substitute). Teece (1986), Profiting from Innovation, commoditization sends profit to the owner of the complementary asset (generic versus specialized). Polanyi, tacit knowledge ("we know more than we can tell"). Taleb, skin in the game (an accountable party is one that can be punished, which AI cannot be). Piketty, r > g (capital income outpaces and concentrates).
Part 5 (the macro cycle). Marx, the realization problem and crisis theory (reset by capital destruction). Keynes, effective demand and the paradox of thrift. Kalecki, the capitalists' dilemma (wages are needed in aggregate but minimized individually). The critique of Say's law, supply creates its own demand, except when the MPC gap breaks it. The MPC and Engel's law, as income falls the necessities share rises (discretionary goods collapse first). Baumol's cost disease, the goods that don't get cheap (housing, healthcare, positional goods) become the binding constraint on real welfare. Ricardo, comparative advantage (even with AI absolutely superior, finite compute leaves low-value tasks to humans). Moravec's paradox, the physical (sensorimotor) is harder to automate than the cognitive. Ford's $5 day, a near-monopolist partly internalizes the demand externality. The fallacy of composition, individually rational, collectively self-defeating.
Parts 10–11 (the pie, the metric). Nordhaus (NBER w10433), producers capture ~2.2% of the social benefit of innovation. Brynjolfsson et al., GDP-B (NBER w25695 / PNAS 2019) and the Stanford Digital Economy Lab (2026), consumer surplus that doesn't appear in GDP. An Amdahl's law for science, the verification loop that runs through the physical bounds the whole.
Scaling: Epoch AI ("Can AI scaling continue through 2030"; "Will we run out of data," Villalobos et al., ICML 2024; the inference-cost study); METR's time-horizon series (the ~7-month doubling of the 50%-reliability task length); the Artificial Analysis Intelligence Index. Robotics / capex / OSS: Goldman Sachs Research (the humanoid 2035 TAM, revised up ~6x, unit cost −40%/yr, a forecast, not a realized value); BMW / Figure AI factory pilots; the VLA manipulation papers (the RoboChallenge generalist at 17.7%; physical/manual work as the least AI-exposed); the toy model placing cognitive ~11.5 years against physical ~92 years (single-author, non-peer-reviewed, self-described rough estimate); Epoch AI on the OSS lag (~3–3.5 months, non-monotonic). Jobs / regulation / welfare: WEF Future of Jobs 2025 (+78M net, ~10M AI-specific); the Anthropic Economic Index; the EU AI Act (Article 4, the high-risk phase-in); C2PA under the Linux Foundation; Nordhaus NBER w10433; Stanford Digital Economy Lab 2026; NBER w25695 / PNAS 2019.
The following failed the 3-vote check and are deliberately not used in the body: model collapse from ~1% synthetic data / a scaling-law break from synthetic contamination; the constant-hazard / half-life interpretation of agent success rates (though the underlying exponential horizon trend survives); the specific "$200B capex versus $12B revenue gap" and "inference unit price collapsing 70%/year"; the older "5–22 month" OSS lag (updated to ~3–3.5 months); the "orders-of-magnitude compute-cost gap" reading of Moravec. Their exclusion is why the report describes the financing structure as fragile rather than declaring a bubble, and why several widely circulated statistics do not appear here at all.